Top - интерактивный мониторинг
Утилита top - одна из наиболее удобных в своей линейке утилит, предназначенная для мониторинга состояния сервера. Ее задача - отобразить общую нагрузку на сервер и его отдельные компоненты.
Вывод утилиты делится на две части: в верхней общая информация о системе, а в нижней - список запущенных процессов и информации о них.
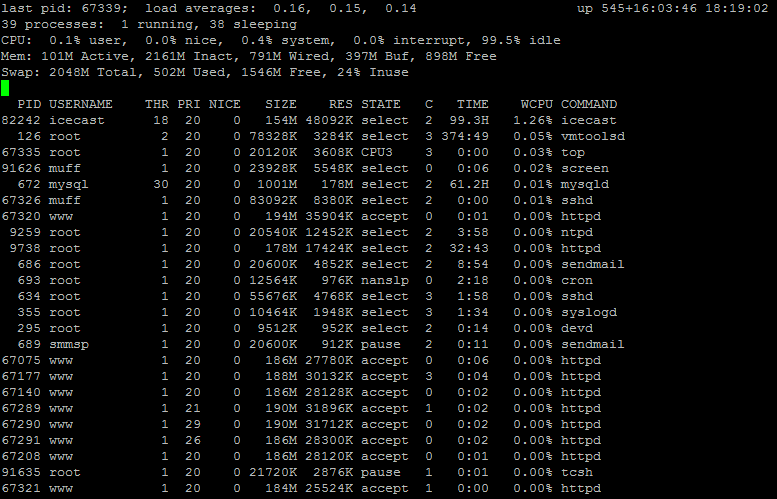
Рассмотрим верхнюю часть вывода утилиты, тоесть, общую информацию о системе.
Использование процессорного времени (CPU):
- user - (User CPU time) время, затраченное на работу процессов пользователей.
- nice - (Nice CPU time) время, затраченное на работу процессов с измененным приоритетом.
- system - (System CPU time) время, затраченное на работу процессов ядра системы.
- interrupt - время, затраченное на работу обработку прерываний.
- idle - простой процессора.
Использования памяти - значения расписаны в статье о структуре виртуальной памяти.
Следующее значение - load average. Это один из важных параметров, поэтому детально его рассмотрим.
Данные load average выводятся в трёх временных интервалах - данные за 1 минуту, за 5 минут и за 15 минут. Эти числа отображают число блокирующих процессов в очереди на исполнение за определенный временной интервал. В данном случае, блокирующий процесс - это процесс, который ожидает ресурсов для продолжения работы. Как правило, происходит ожидание таких ресурсов, как центральный процессор, дисковая подсистема или сетевая подсистема. Высокие значения показателей load average говорят о том, что система не справляется с нагрузкой. Но как узнать какое значение load average является нормальным? Всё зависит от количества ядер.
Рассмотрим ситуацию, когда у нас CPU с одним ядром, отталкиваясь от значений load average во временных интервалах за 5 и 15 минут.
| Load average | Состояние системы |
| < 0.7 | Все в порядке. Система практически не нагружена |
| 0.7 - 1 | Система нагружена. Следует найти и определить причину нагрузки системы для избежании проблем в дальнейшем. |
| 1-5 | Система сильно нагружена. Необходимо в срочном порядке определить причину высокой нагрузки и устранить ее. |
| > 5 | Система критически нагружена. Сервер может подвисать и работать очень медленно, при обработке запросов "торможения", доступ к серверу затруднён. |
Обратите внимание, что высокий показатель load average может быть вызван большим количеством процессов, выполняющих в данный момент операции чтения/записи. То есть, load average > 1.00 на одноядерной машине не всегда говорит о том, что в системе отсутствует запас по загрузке процессора. Требуется более детальный анализ ситуации.
Также, стоит обратить внимание на тот факт, что максимальная производительность системы достигается при load average > 1, тоесть, в отдельных случаях есть смысл держать load average повыше, чтобы более эффективно нагрузить "железо", в ущерб времени обработки отдельного запроса.
Еще один важный аспект. При load average больше 5, работа системы расценивается как неустойчивая. Некоторые демоны прекращают приём новых запросов при высоких уровнях загрузки (например Sendmail прекращает приём запросов при load average равным или больше 12). Если загрузка достигает 20-30, то скорей всего система окажется в ситуации, называемой "спираль смерти", т.е. новые процессы создаются быстрее, чем система может их выполнить. "Death Spiral" - один из редких случаев, когда может понадобится перезагрузить сервер.
Обратите внимание на отображениее load average в мультипроцессорных системах. В мультипроцессорных системах загрузка вычисляется относительно количества доступных процессорных ядер. 100% загрузка обозначается числом 1.00 для одноядерной машины, числом 2.00 для двуядерной, 4.00 для четырехъядерной и т.д.
Продолжим изучение утилиты top. В нижней части вывода, мы можем получить следующую информацию о процессах.
- PID - идентификатор процесса.
- USERNAME - пользователь, от которого запущен процесс.
- THR - количество потоков, запущенных процессом.
- PRI - текущий приоритет процесса.
- NICE - приоритет, выставленный командой nice.
- SIZE - полный размер процесса (данные, стек и т. д.)
- RES - размер процесса в оперативной памяти.
- STATE - текущее состояние процесса: "START", "RUN", "SLEEP", "STOP", "ZOMB", "WAIT" или "LOCK". Текущая нагрузка отображается только в состояниях "START" и "RUN".
- C - номер процессора, на котором идет выполнение (только на SMP системах).
- TIME - время использования процессора (в секундах).
- WCPU - усредненное значение использования CPU.
- COMMAND - команда, запустившая процесс.
При использовании утилиты top, поддерживаются ключи, для работы в интерактивном режиме, которые сортируют, фильтруют или видоизменяют вывод. Рассмотрим некоторые из них
- a - показать абсолютные пути запущенных процессов.
- С - переключение между режимами отображения "raw cpu" и "weighted cpu".
- H - включает/выключает отображение потоков.
- h - отображение окна справки.
- i - скрыть/отобразить отображение простаивающих процессов.
- j - скрыть/отобразить jail ID.
- J - отображение процессов только указанного jail.
- k - уничтожить процесс (запрашивает PID процесса).
- m - переключение между режимами отображения нагрузки (процессор, память) и загрузки системы ввода-вывода.
- n - изменить число отображаемых процессов (предлагается ввести число).
- o - сортировка по столбцам pri, size, res, cpu, time, thr.
- P - показывать статистику загрузки по каждому процессору отдельно (для SMP систем).
- r - изменить приоритет процесса.
- S - показать/скрыть системные процессы (по умолчанию они скрыты).
- s - установить время обновления вывода информации (в секундах).
- t - скрыть/отобразить процесс top.
- u - отфильтровать по имени пользователя (запрос на имя пользователя).
- [Пробел] - немедленно обновить содержимое экрана


Re: Top - интерактивный мониторинг
Спасибо